BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Transformer의 주요 활용 사례로 언급되는 BERT 모델 리뷰
논문 개요
- 제목: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- 기관: Google AI Language
- 발표: 2018.10
- 인용수: 110,833회 (2024.09.03 기준)
- 코드: google-research/bert
핵심 내용 요약
- BERT (Bidirectional Encoder Representations from Transformers) 모델 제안. 크게 다음 두 step으로 구성됨.
- pre-training: unlabeled text data에서 deep bidirectional representation 학습
- fine-tuning: 하나의 output layer만을 추가해, 특정 downstream task에 대해 labeled data 이용해 transfer learning
- 결과: 11개의 주요 NLP task에서 SoTA 달성 (토큰수준, 문장수준 Task 모두)
- 연구의의: task-specific architecture보다 저렴하면서도 뛰어난 성능 보이는 첫번째 fine-tuning 기반 representation 모델
주요 용어 정리
-
self-supervised learning
- 등장 배경: labeled data 수집 어려움
- 비지도학습 기법 중 하나로, unlabeled data로부터 스스로(self) 학습하는 기법
- label이 불필요한 대신, 데이터 자체에서 학습 task를 생성한다. 이를 통해 모델이 데이터의 내재된 구조와 피턴을 이해하도록 돕는다.
-
transfer learning
 이미지 출처: https://www.aismartz.com/blog/an-introduction-to-transfer-learning/
이미지 출처: https://www.aismartz.com/blog/an-introduction-to-transfer-learning/- 한 분야의 문제를 해결하기 위해 얻은 지식과 정보를 다른 문제를 푸는데 사용하는 방식
- pre-trained model을 labeled data로 재학습시키는 것
- Standing on the shoulders of giants 라는 문구에 비유 가능
- 강의자료에서는 pre-trained 모델을 downstream task에 대해 ‘fine-tuning’하는 방법론이라고 표현했지만, 엄밀하게는 transfer learning의 방법 중 하나가 fine-tuning임
-
pre-training
- 사전에 모델을 학습하는 것 (주로 self-supervised learning 기법 이용)
- model learned from scratch
- 데이터로부터 유의미한 지식(feature) 배웠을 것이라는 가정 내포
-
fine-tuning
- 얻고자 하는 결과값이 pre-trining에서와는 다를 것. 따라서 마지막 output layer를 삭제하고 downstream task에 맞는 layer를 붙여서 학습시키는 방법.
- task-specific (fine-tuned) parameter 수는 최소화하고, 모든 pre-trained parameter를 조금만 바꿔서 downstream task를 학습함
- 모델 끝 단을 바꿔끼운 모델의 전체 parameter를 업데이트 할 수도 있고, 새로 더해진 layer의 parameter만 학습해 붙일 수도 있음
- 새로 학습에 사용되는 데이터셋이 적거나, pre-trained model에서의 목적과 비슷하지 않다면 성능 안좋을 수 있음
-
objective function
- 학습을 통해 최적화시키려는 함수
- loss function, cost function 등은 objective function의 한 종류임
모델 등장 배경
BERT 이전의 transfer learning 연구
- BERT 이전에도 Language model의 pre-training은 다수 NLP task에서 우수한 성능 보여왔음
- 문장 수준 task: 문장의 관계 전체적으로 분석해 예측하는 것을 목표로 하는 task (예: NLI, paraphrasing)
- 토큰 수준 task: 토큰 수준의 세분화된 출력을 생성하는 task (예: NER, QA)
- feature-based approach, fine-tuning approach의 두 가지 주요 접근 존재했음
Feature-based approach
- task-specific architecture를 구성하고, downstream task 학습 시 pre-trained representation (즉, embedding layer)를 부가적인 feature로 사용하는 방법
-
대표적인 예시: ELMo (Embeddings from Language Model)
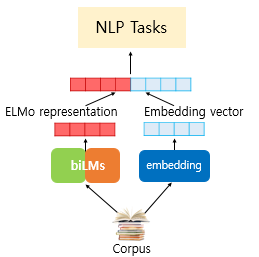
- 문맥에 따른 단어의 의미 차이 반영해 모델 학습시키는 방법.
- 예를 들어 Bank Account(은행 계좌)와 River Bank(강둑)에서의 Bank가 서로 다른 의미임을 모델이 학습하도록 함 (기존의 Word2Vec 방식에서는 이런 문맥에 따른 단어의 의미 차이 반영하지 못함)
- ELMo를 기준으로 Feature-based approach를 설명하겠다.
-
Step 1. 문맥을 반영해 word embedding
- 각 층의 출력값이 가진 정보는 전부 서로 다른 종류의 정보를 갖고 있을 것이므로, 이들을 모두 활용한다
- biLM: 이를 위해, 순방향과 역방향 언어 모델을 별개의 언어모델로 보고 각각 학습 진행한다
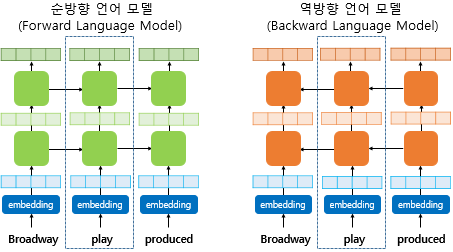
- ELMo representation: 순방향, 역방향 LM 각각에서 해당 time step의 biLM의 각 층의 출력값 가져와 concat하고, 가중합한다
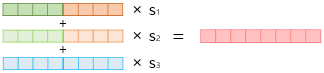
-
Step 2. shallow bidirectional
- BiLM 통해 얻은 ELMo representation과 기존 임베딩 벡터를 concat해서 input으로 사용한다.
- shallow: 순방향과 역방향 언어 모델을 모두 사용하므로 bidirectional LM으로 생각할 수 있지만, 단방향인 LM 2개의 출력값을 이어붙인 것 뿐이다. 따라서 ‘shallow’ bidirectional로 명명하며, 이는 BERT에서의 ‘deep’ bidirectional과 차이를 갖는다.
Fine-tuning approach
- contextual token representation을 만들어내는 (문장 혹은 문서)인코더가 pre-training 되고, supervised downstream task에 맞춰 fine-tuning 되는 방식
- 대표젹인 예시: OpenAI GPT
- 장점: scratch로 (처음부터) 학습하는데 비해 적은 파라미터로도 충분
- 단점: pre-training 과정에서 general language representation 학습 위해 unidirectional language model 사용
기존 연구의 한계: 단방향(unidirectional) 제약
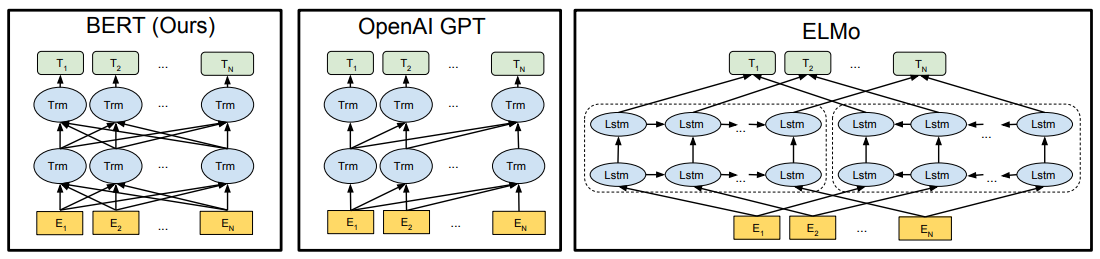
- 기존 방식은 unidirectional 이라는 점에서 pre-training 중에 사용할 수 있는 architecture 구조가 제한되어 pre-trained representation의 성능 제한
- 특히 GPT의 경우, 모든 토큰이 이전 토큰들과의 attention으로만 계산하므로(constrained self-attention) 토큰이 아닌 문장 수준의 정보를 반영해야 하는 다음 문장 예측 task나, 양방향의 context 통합이 중요한 QA task와 같은 토큰 수준 작업에서 성능 한계 보임
- 본 논문에서는 특히 fine-tuning 접근방식에 집중, 기존의 unidirectional 문제 개선해 deep bidirectional context를 반영하는 BERT 제안 (bidirectional self-attention)
GPT는 next token prediction에 초점을 맞추어 Transformer decoder (left-context-only version)만을 사용했고, BERT는 MLM 및 NSP를 위해 self-attention을 수행하는 Transformer encoder (bidirectional Transformer)만을 사용했다.
모델 구조
Multi-layer bidirectional Transformer encoder
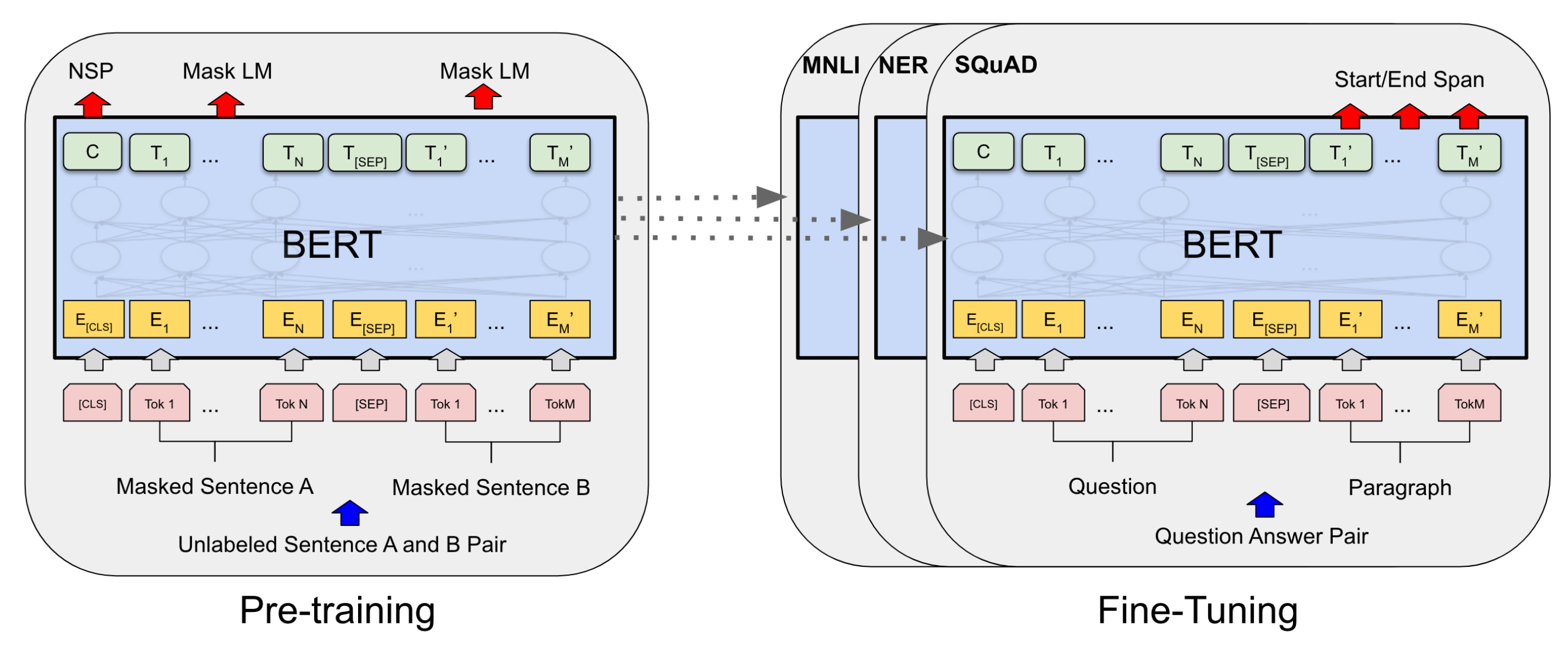
- 양방향 Transformer encoder를 여러 층 쌓음
- 다양한 Task에 대해 통합된 architecture
- Output layer를 제외하고는 pre-training과 fine-tuning 모두에 동일한 아키텍처가 사용됨
- 서로 다른 downstream task에 대해, 항상 동일한 pre-trained model의 파라미터가 초기값으로 사용되고, fine-tuning 과정에서 이 파라미터들이 downstream task에 맞게 조정됨
- 특수 토큰
-
[CLS]: 모든 input example 앞에 추가되는 특수 토큰. NSP에서 사용됨 -
[SEP]: 특수 구분 토큰 (예: 질문/답변 구분)
-
- notation
- $L$: layer(즉, transformer block)의 수
- $H$: hidden size
- $A$: self-attention head의 수
- $E$: input embedding
- $C \in \mathbb{R}^H$: 특수 토큰
[CLS]의 최종 hidden vector - $T_i \in \mathbb{R}^H$: $i$번째 input token에 대한 최종 hidden vector
- 본 논문에서는 2가지 모델 크기 고려
- $\text{BERT}_{\text{BASE}}$: $L=12$, $H=768$, $A=12$, 전체 파라미터 110M개
- $\text{BERT}_{\text{LARGE}}$: $L=24$, $H=1024$, $A=16$, 전체 파라미터 340M개
Step 0. Input/Output Representation
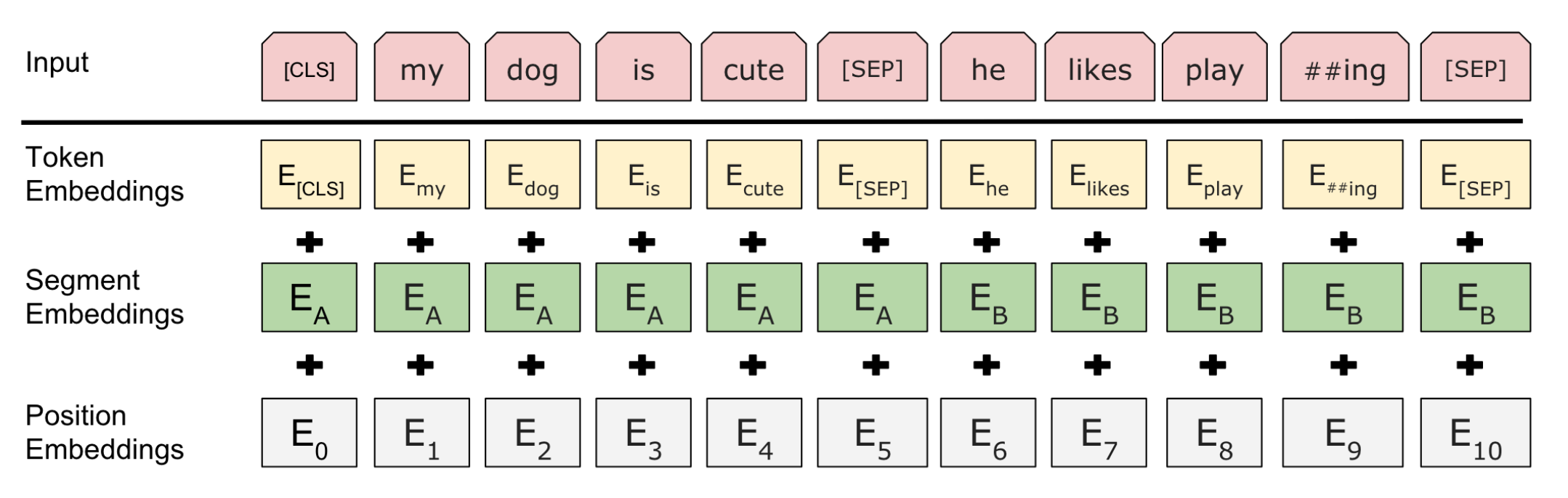
- input sequence는 하나의 문장일 수도, 두 문장의 쌍일 수도 있음 (QA 등의 다양한 downstream task 처리하기 위해 한가지 형태로 제한하지 않음)
- 문장 쌍의 각 문장은
[SEP]토큰으로 구분됨
- 문장 쌍의 각 문장은
- 3가지의 embedding vector 합쳐서 input representation으로 사용 (token/segmentation/position embedding)
- 모든 시퀀스의 첫번째 토큰은 항상
[CLS]토큰 - token embedding: WordPiece 임베딩 (3만 개의 토큰 어휘 사용)
- segmentation embedding: 각 토큰이 문장 A에서 나왔는지, B에서 나왔는지 구분하기 위함
- position embedding: 단어의 위치 구분하는 임베딩
- 모든 시퀀스의 첫번째 토큰은 항상
WordPiece 임베딩은 BPE(Byte Pair Encoding)의 변형 알고리즘이다. 빈도수에 기반해 가장 많이 등장한 쌍을 병합하는 BPE와는 달리, WordPiece는 병합되었을 때 corpus의 likelihood를 가장 높이는 쌍을 병합한다.
Step 1. Pre-Training BERT
- Masked LM(MLM)과 Next Sentence Prediction(NSP)의 두 가지 unsupervised-task 동시에 사용해 pre-training 수행
- 해당 task들 통해 단방향성 제약이 완화됨 (ablation study 통해 확인)
Task 1: Masked LM (MLM)
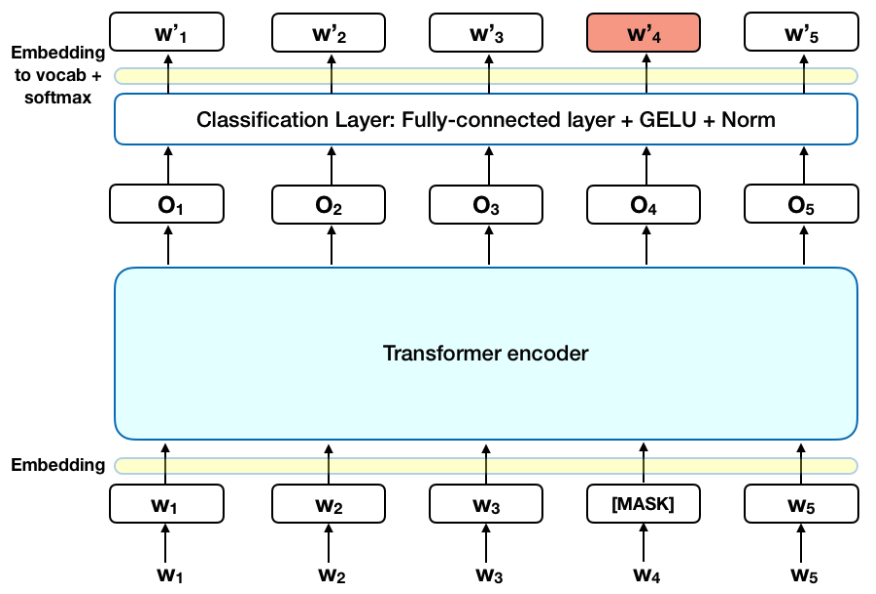
- 아무런 제약 조건 없이 bidirectional하게 학습 하면, 간접적으로 예측 대상 단어를 참조하게 되어 학습이 어려움. 이에 penalty 부여하는 방법으로써 MLM task 도입함.
-
MLM: input token의 일정 비율을 랜덤하게 마스킹하고, context 통해 이 마스킹된 토큰을 예측하는 task
- Cloze Test (빈칸 채우기 테스트)에서 영감 얻음
- 예:
오늘, 나는 ___에 가서 우유와 계란을 샀다. 비가 올 줄 알았지만 ___을 챙기는걸 잊어서 가는 길에 젖었다(마트, 우산)
- 예:
- 마스킹된 구절에 속하는 올바른 언어/품사 식별 위해서는 context와 어휘 이해하는 능력이 필요
- Cloze Test (빈칸 채우기 테스트)에서 영감 얻음
- 각 입력 시퀀스의 15% 토큰을 무작위로 마스킹 (15%라는 수치는 경험적으로 결정)
- BERT는 오직 이 마스킹된 토큰만을 예측 (문장 복원 아님 유의)
-
[MASK]토큰은 Pre-training에서만 사용됨 -> pre-training과 fine-tuning 사이의 불일치 완화하기 위해 일부는[MASK]가 아닌 다른 토큰으로 마스킹함-
80%:
[MASK]토큰 (예: my dog is hairy -> my dog is[MASK]) - 10%: 랜덤 토큰 (예: my dog is hairy -> my dog is apple)
-
10%: 원래 토큰 (예: my dog is hairy -> my dog is hairy)
- 실제 관측 단어에 대한 representation을 bias해주기 위함
-
[MASK]와 랜덤 토큰만 사용하면, 모델이 ‘무조건 새로운 단어로 바꾼다’고 학습할 수 있으므로
-
80%:
- 마스킹된 토큰에 대응되는 최종 hidden vector $T_i$를 이용해 cross entropy loss 기반으로 원래 토큰 예측
Task 2: (binarized) Next Sentence Prediction (NSP)
- 많은 NLP downstream task(QA, NLI 등)의 핵심은, 두 문장 간의 관계를 이해하는 것
- 이를 위해 문장 A의 뒤에 문장 B가 실제 이어지는 문장인지 예측함
- 연속된 문장 쌍과, 그렇지 않은 문장 쌍(corpus에서 랜덤하게 선택)을 1:1 비율로 입력해 학습시킴
- 연속된 문장쌍 input sequence (label:
IsNext)[CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP]
- 불연속 문장쌍 input sequence (label:
NotNext)[CLS] the man [MASK] to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
- 연속된 문장쌍 input sequence (label:
- $C$는 특수 토큰
[CLS]의 최종 hidden vector로써, input으로 들어온 두 문장이 원래 연속된 문장인지(IsNext) 아닌지(NotNext)를 맞춰가며 학습 - 논문의 Ablation Study에서는 해당 NSP 학습이 없으면 모델 성능 감소한다고 명시함
Pre-training data
- pre-training 과정은 많은 데이터를 필요로 함. 본 논문에서도 역시 대량의 unlabeled data로 학습을 진행 (self-supervised learning)
- corpus를 구축하기 위해 BookCorpus(800M)와 English Wikipedia (2,500M)를 사용함
- 기존 pre-trained LM의 접근방식 따름
Step 2. Fine-Tuning
- parameter를 pre-trained parameter로 초기화한 뒤, downstream task에 대한 labeled data 이용해 parameter를 fine-tuning
- fine-tuning은 pre-training에 비해 훨씬 저렴함 (대부분의 task에서 TPU 1시간, GPU 몇시간 이내 소요)
- downstream task별 input, output
- entailment: 가정-전제 쌍의 함의 관계에 대한 분류 task (내포/모순/무관 중 하나로 분류)
- tagging: 문장의 각 단어에 대한 품사 태깅, entity 태깅 (NER) 등
- text classification: 문장 간의 관계를 예측
| downstream task | input (pairs) | output |
|---|---|---|
| paraphrasing | sentence | |
| entailment (classification) |
hypothesis-premise | [CLS] representation |
| QA | question-passage | token representation |
| text classification / sequence tagging |
degenerate-none | token representation |
실험 결과
GLUE (General Language Understanding Evaluation)
- 다양한 자연어 이해 task의 모음
-
참고: GLUE leaderboard
2024.09 현재 시점에서는BERT가 49위
-
참고: GLUE leaderboard
- $\text{BERT}{\text{BASE}}$와 $\text{BERT}{\text{LARGE}}$ 모두 기존 방법보다 우수한 성능 보임
- $\text{BERT}_{\text{BASE}}$와 OpenAI GPT는 attention masking을 제외하고 모델 아키텍처 측면에서 거의 동일하다는 점에서 흥미로운 결과.
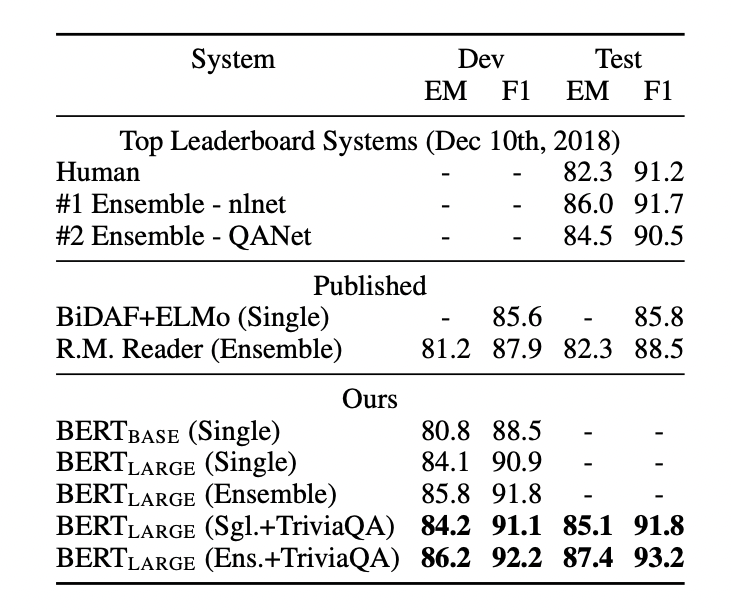
SQuAD(Stanford Question Answering Dataset)
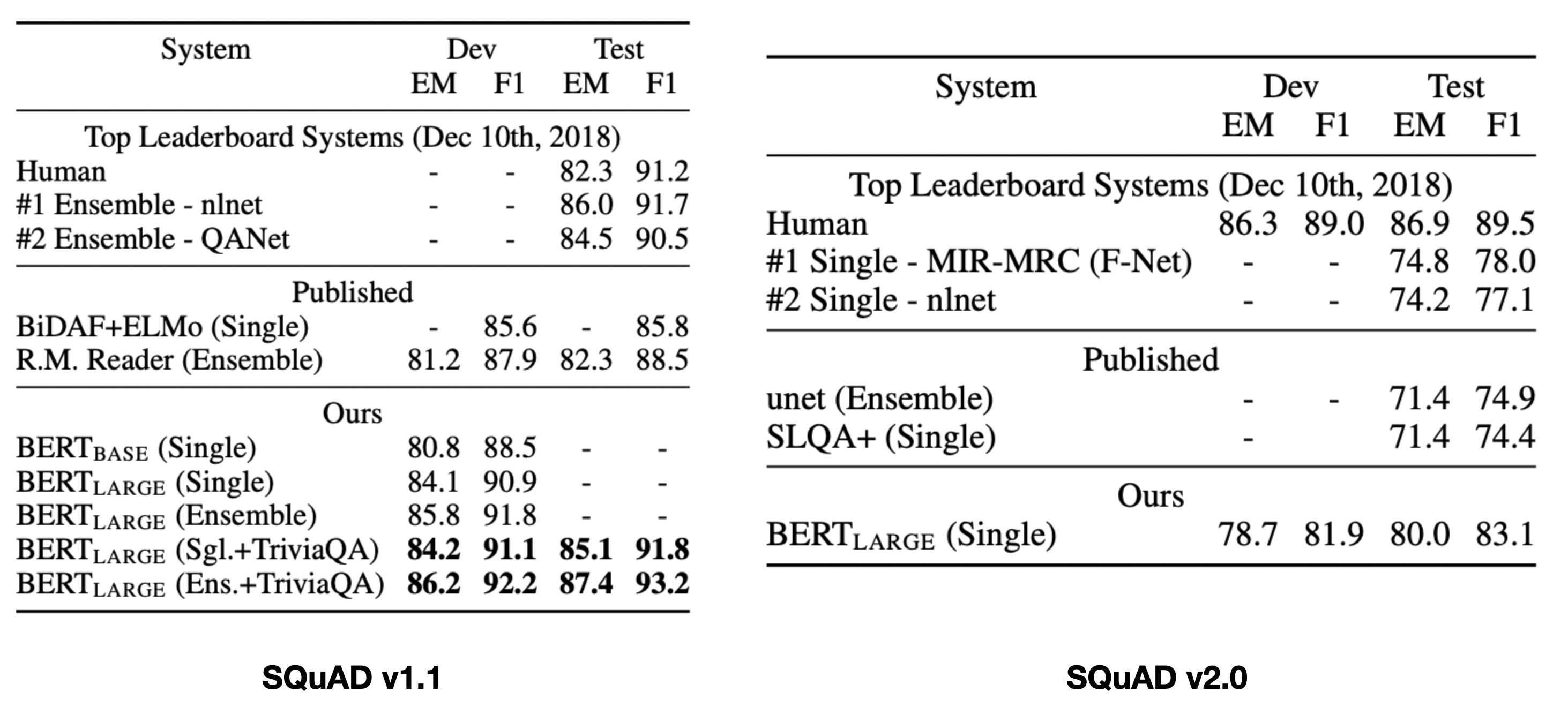
- (question, passage) 데이터 주어지면 passage 내에서 answer span을 예측하는 task
- 정답의 시작과 끝 토큰 예측하는 classifier 사용
- v1.1: passage에 답변 항상 존재
-
v2.0: v1.1을 확장해서, passage에 답변 없을 가능성 허용
- 정답이 없는 문제의 answer span:
[CLS]~[CLS] - 인간만큼은 아니지만, 기존 baseline에 비해서는 우수한 성능 확인
- 정답이 없는 문제의 answer span:
SWAG (Situations With Adversarial Generations)
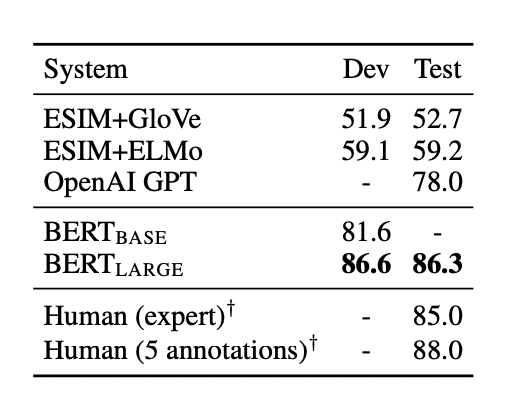
- 상식 추론: 문장이 주어지면, 4개의 선택지 중 가장 그럴듯하게 이어지는 문장 고르는 task
- 역시나 좋은 성능 보임
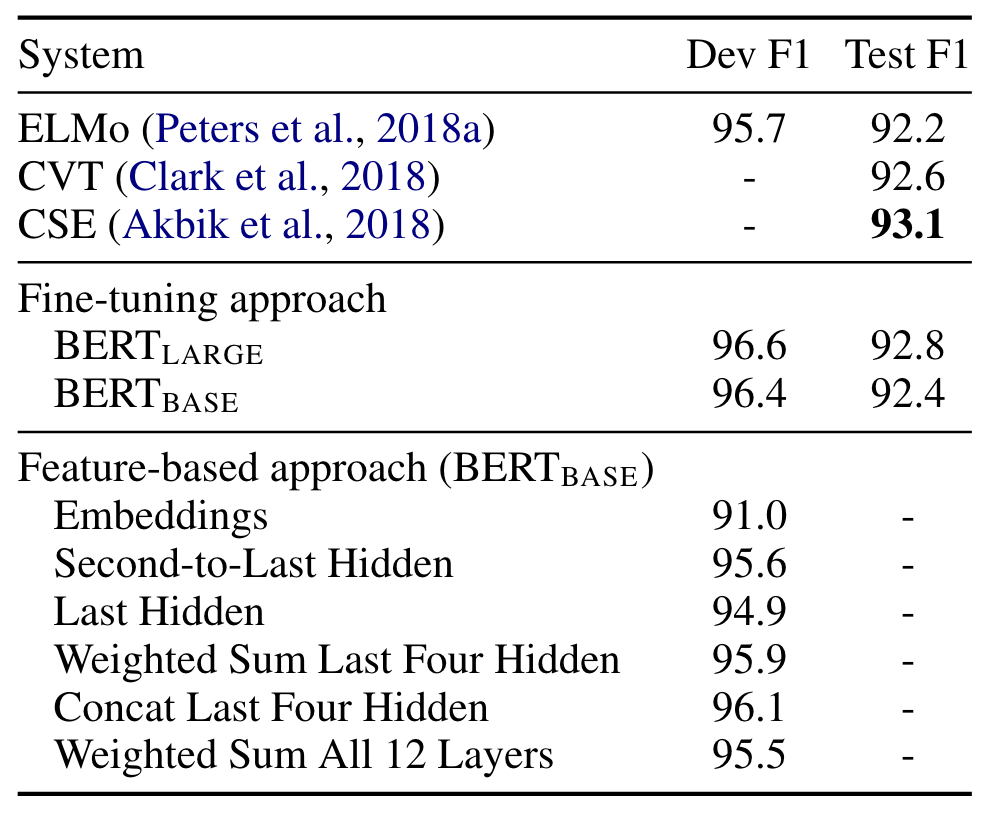
Ablation Studies
- BERT의 facet의 상대적 중요성 이해하기 위해 3가지 제거 실험 수행함
- pre-training task의 영향 (MLM, NSP): 중요함
- 모델 크기의 영향: 모델 클수록 성능 좋음
- BERT의 feature 기반 접근방식: fine-tuning과 성능 유사함
- BERT의 feature 기반 접근방식
- BERT는 fine-tuning 및 feature-based approach 모두에서 효과적임
Review
느낀점
- 이름은 익숙했지만 어떤 방식으로 작동하는지 잘 몰랐던 BERT 모델의 구조 알게돼서 재미있었음. Transformer의 확장이라 그런지, 모델 구조를 수식적으로 이해하기보다는 아이디어를 이해하는게 더 핵심이었던 논문이라고 생각함
- BERT 기반 모델을 몇번 사용했었는데, 항상 pre-trained 모델을 그대로 가져다 썼었다. fine-tuning도 해봤으면 좋았겠다는 아쉬움이 생겼다. BERT를 쓰면서 그 기능의 절반밖에 이용을 못했던 느낌..
- 막연히 알고있던 pre-training, fine-tuning, downstream task 등의 용어 되짚어볼 수 있었다. 이들 확인하다보니, fine-tuning의 다양한 전략들이 궁금해졌다. LoRA tuning과 일반적인 fine-tuning의 차이점도 궁금해졌다.
Action Plan
- BERT 모델 가져와서 fine-tuning 및 평가해보기. 어떤 방식으로 돌아가는지 코드로도 확인해보자.
- fine-tuning의 다양한 방식 살펴보기
Reference
This post is licensed under CC BY 4.0 by the author.
Comments powered by Disqus.