TAG (Table-Augmented Generation)
DB와 LM을 결합하는 새로운 패러다임인 TAG의 작동 순서를 살펴본다
개요
-
cue: (240909 AI타임스) 데이터베이스와 LLM 지식 통합하는 ‘테이블 증강 생성’ 기술 등장 기사
- 데이터베이스에 대한 자연어 QA에 답하는 새로운 패러다임으로서 TAG(Table-Augmented Generation)라는 방법론이 제안되었다고 함
- 동일한 문제를 풀고자 하는 기존의 Text2SQL, RAG 방법론에 비해 어떤 차이점, 장점 갖는지 궁금해 살펴봄
-
reference: 논문, 코드
- UC 버클리, 스탠포드대학교 연구진
TAG 제안 배경
Task
- task: (input) 사용자의 자연어 질문 -> (output) 자연어 답변
- 기존 접근방식(Text2SQL, RAG)의 한계
- 특정 쿼리에 제한되므로 의미적 추론이나 데이터 소스에서 직접 얻을 수 있는 것 이상의 지식을 요구하는 자연어 쿼리 처리에 어려움
-
Text2SQL: 자연어 쿼리를 SQL로 변환하는 방법으로서, 관계 연산으로 표현 가능한 자연어 질문만 처리 가능
- 예1: “A라는 고객 리뷰는 긍정적이야?” -> 긍부정에 대한 field 없으면 답변 힘듦
- 예2: “B제품의 매출 감소 이유는 뭐야?” -> 여러 table 항목에 걸쳐 정보 집계해야 하는 추론 과정 필요하므로 답변 힘듦
-
RAG: 웹 데이터를 찾아 LLM의 답변 생성에 참조하는 방식
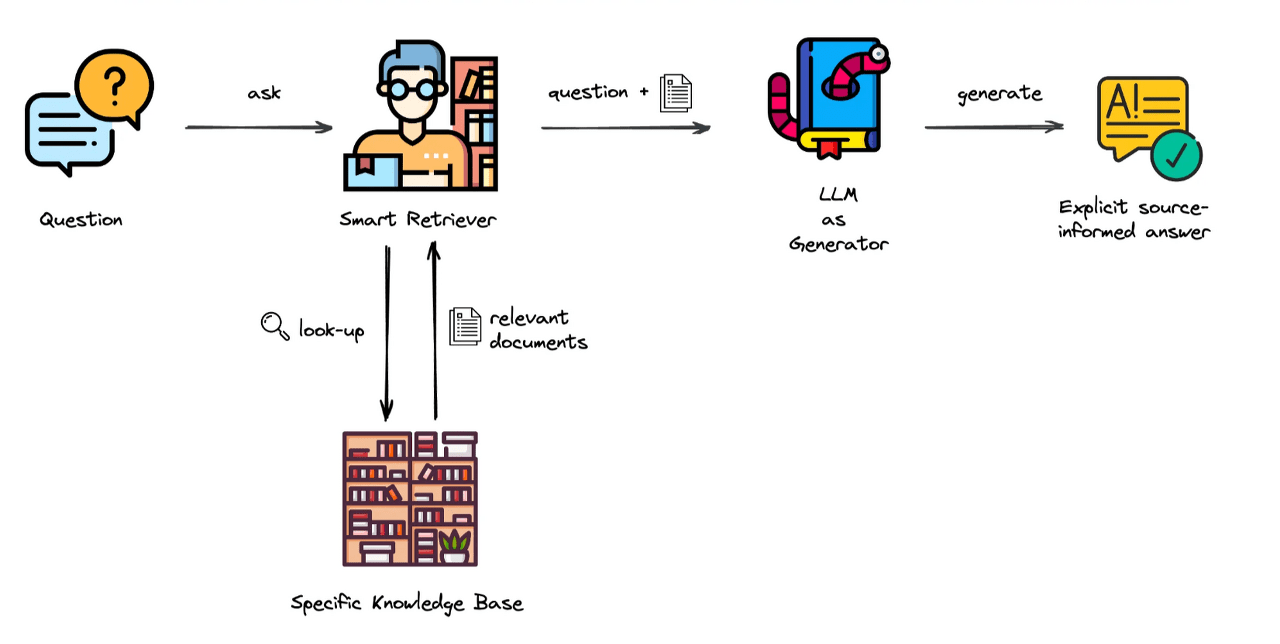
- 관련성을 기반으로 몇 개의 데이터 가져와서(point lookup), 한 번의 LM 호출로 결과 생성함
- 소수의 데이터 기록 찾아, 답변 가능한 질문만 고려함
- 많은 DB 시스템의 풍부한 쿼리 실행 기능 활용하지 못함
- 계산, 필터링, 집계 등의 작업을 LM에게 맡겨서, 오류 발생 가능성 높고 비효율적임
- 단순하고 직접적인 질문에는 효과적이지만, 복잡한 분석이나 대량의 데이터를 처리해야 하는 작업에는 제한적
- 복잡한 질문, 계산이 필요한 작업 등에서는 잘 작동하지 못함
- 예1: “16세기에 쓰인 영국 희곡 중 가장 인기 있는 작품은 무엇인가요?” -> 여러 책을 비교 분석해야 하는 작업이므로 답변 힘듦
- 예2: “100인분의 파스타 카르보나라를 만들려면 재료가 얼마나 필요한가요?” -> 계산 필요하므로 답변 힘듦
TAG
- 데이터베이스(DB)와 대형언어모델(LLM)의 추론 기능을 결합하는 접근방식
- 이를 통해 복잡한 쿼리에 대응하는 효과적인 시스템 만들고자 함
- 의미적 추론이나 데이터 소스에서 직접 얻을 수 있는 것 이상의 지식을 요구하는 자연어 쿼리 처리할 수 있게 됨
Model Structure
- (input) 자연어 Request $R$ -> (output) 자연어 answer $A$
- 3개 단계의 single iteration으로서 TAG 정의하지만, multi-hop 방식으로의 확장도 고려 가능
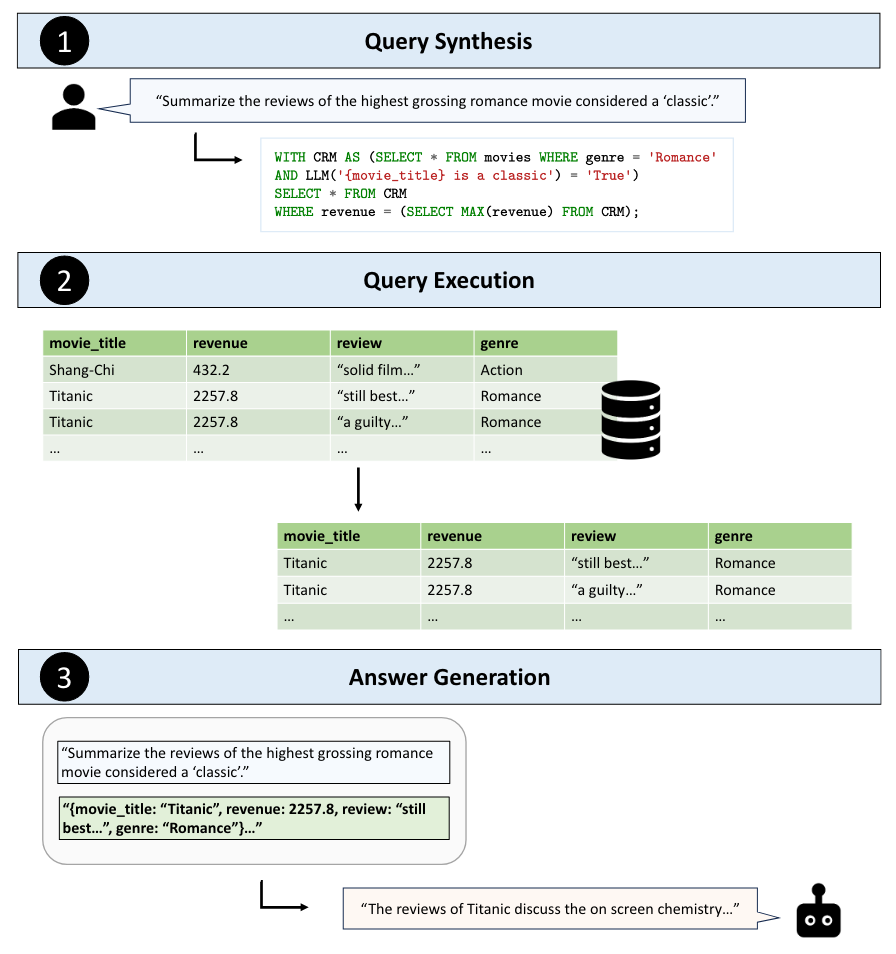 ‘최고 수익을 올린 고전 로맨스 영화의 리뷰 요약해줘’ 질문에 대한 TAG 작동 방식 예시
‘최고 수익을 올린 고전 로맨스 영화의 리뷰 요약해줘’ 질문에 대한 TAG 작동 방식 예시
Step 1. 쿼리 합성 (Query Synthesis)
- 사용자 질문을 실행 가능한 데이터베이스 쿼리로 변환
- 세부 step
- 테이블 스키마 등 사용해서 사용자 질문과 관련 있는 데이터 추론
- LM 활용해 사용자 질문을 DB 시스템에서 실행 가능한 쿼리로 변환
- (예시) “최고 수익을 올린 고전 로맨스 영화의 리뷰 요약해줘”
- 장르에 대한 표준 필터 사용해 로맨스 영화 찾기
- LM의 세계 지식 활용해 각 영화가 ‘고전’인지를 식별함 (기존 Text2SQL, RAG에서는 어려웠던 작업)
- 수익에 따라 결과에 순위 매겨, 가장 높은 수익 올린 영화 찾음
자연어 질문을 입력받아 SQL engine에서 실행 가능한 SQL 쿼리를 생성한다는 점에서 Text2SQL과 비슷하다. 하지만 Text2SQL는 생성하는 SQL 쿼리를 통해 해당 자연어 질문의 정답을 직접 바로 얻고자 하는 반면, TAG는 LLM에서 최종 정답 생성 시 참고할 단서 정보를 추출하고자 하는데 차이가 있다.
Step 2. 쿼리 실행 (Query Execution)
- DB 시스템에서 쿼리를 실행해 관련 데이터(테이블) 얻음
- (예시) 타이타닉에 대한 리뷰 데이터 얻음
Step 3. 답변 생성 (Answer Generation)
- 사용자 질문과, step 2에서 생성된 데이터를 사용해 LM으로 자연어 답변 생성
- 데이터는 모델이 처리할 수 있도록 문자열 형태로 인코딩되어 LM에 전달
- LM의 의미론적 추론 기능 활용해 answer 생성
연구 시사점
- LM의 추론 능력이 쿼리 합성 및 답변 생성 단계 모두에 통합됨
- 의미적 추론, 세계 지식, 도메인 지식을 모두 요구하는 복잡한 질문에 답할 수 있게 됨
- TAG 평가를 위한 벤치마크셋을 직접 구성했고, 기존의 Text2SQL, RAG 방법들보다 성능 우수하다고 보고함
- 기존 접근법은 20% 이하의 정확도, 이 TAG는 약 60% 안팎의 정확도 보인다고 보고함 (
아직 갈 길이 멀다..!)
- 기존 접근법은 20% 이하의 정확도, 이 TAG는 약 60% 안팎의 정확도 보인다고 보고함 (
느낀점
- 언어모델의 한가지 주요 활용 사례 확인: 직접 드러나지는 않더라도, LM을 이용한 쿼리문 작성이라는 아이디어는 중요하고, 자주 사용되는 것 같다. 이전에 가볍게 봤던 Recommender AI Agent 논문에서도 추천 시스템에서 추천 후보가 되는 item들을 가져올 때, LLM을 이용으로 작성된 쿼리문을 사용하는걸 보기도 했다. 언어모델의 한가지 주요 활용 사례를 알게 됐다.
- text2sql 관련 내용을 찾아보다가, 우아한형제들에서 작성한 관련 포스팅(AI 데이터 분석가 ‘물어보새’ 등장 – 1부. RAG와 Text-To-SQL 활용)을 확인했다. 이런 ‘LM을 활용한 SQL문 작성’의 아이디어를 어떻게 구체화해서 서비스 형태로 발전시켰는지 구체적으로 작성되어있어 흥미로웠다. 또한, LLMOps 관점에서도 pipeline을 제시해주어, 각 단계 별로 활용할 수 있는 툴을 참고할 수 있었다. MLOps를 공부하기 시작한 관점에서 보니 이것도 흥미로웠던 부분.
Reference
This post is licensed under CC BY 4.0 by the author.
Comments powered by Disqus.